STL无序容器概述
哈希算法
hashtable:在插入,删除,搜寻操作上具有常数平均时间的表现,不需要依赖元素的随机性
解决哈希冲突问题(不同的元素被映射到同一个位置)
线性探测法
负载系数:元素个数、表格大小,永远在0-1之间,除非采取开链策略
当hashfunction计算出某个元素的插人位置,而该位置上的空间已不再可用时,我们应该怎么办?最简单的办法就是循序往下一一寻找(如果到达尾端,就绕到头部继续寻找),直到找到一个可用空间为止。只要表格(亦即array)足够大,是能够找到一个安身立命的空间,但是要花多少时间就很难说了。
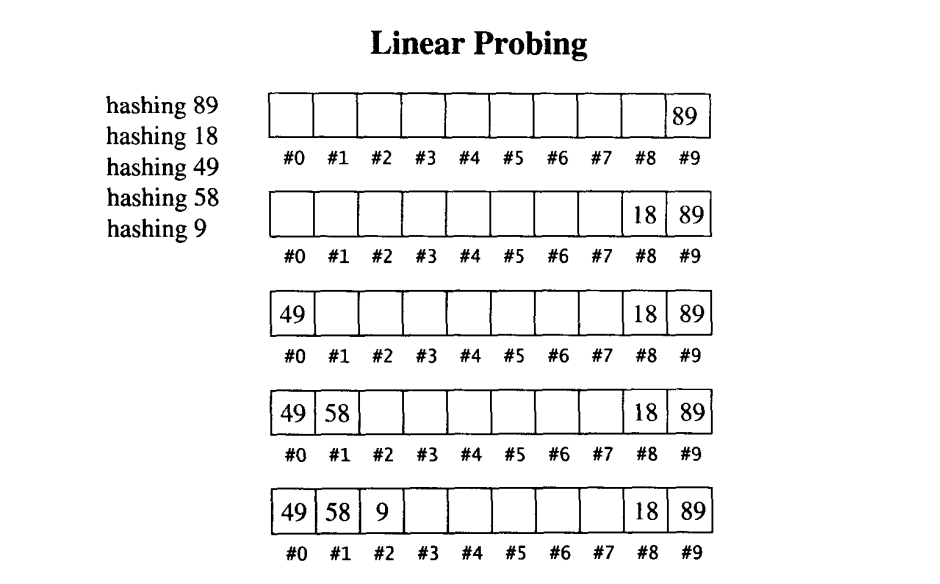
平均插入成本的成长幅度,远高于负载系数的成长幅度。这样的现象被称为“主集团”。有一大杯被使用过的放个,插入操作极有可能在主集团中“奋力爬行”。
二次探测法
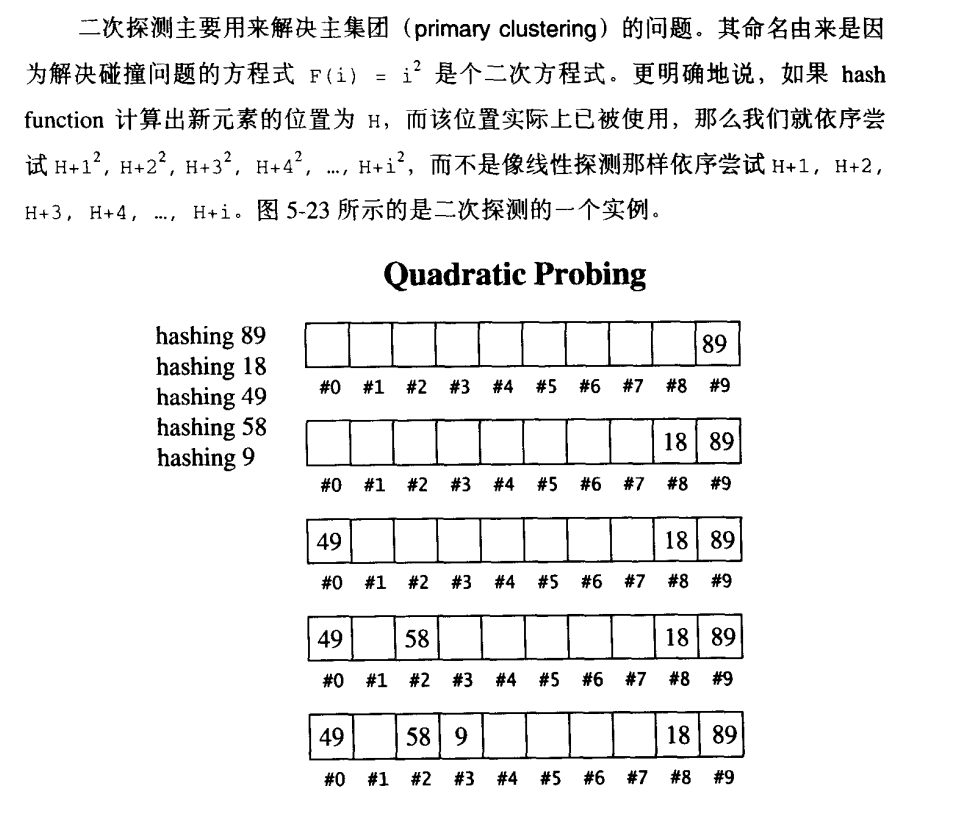
疑问:如何保证插入操作一定能够成功?
如果我们保持表格大小为质数,永远保持负载系数在0.5以下,就可以确定插入元素的探测次数不超过2
二次探测可以消除主集团问题,但也有可能造成次集团问题:两个元素经过hashfunction计算出来的位置相同,则插入时探测的位置也相同。
开链
在表格每个元素中维护一个list,然后在哪个list上执行插入,搜寻,删除。如果list够短,速度还是块。同时负载系数上限就不为1了。
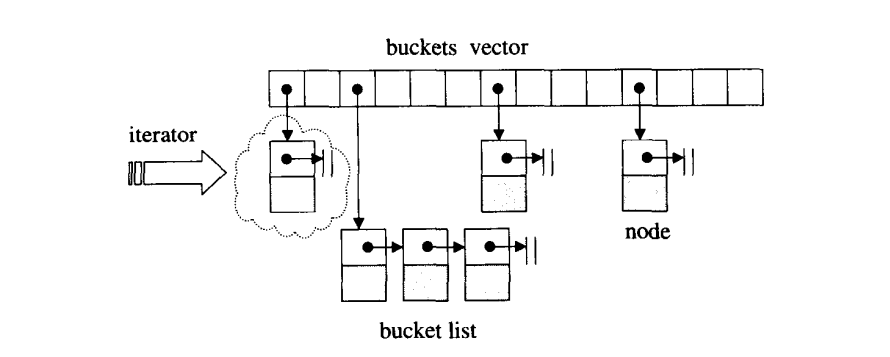
hashtable迭代器必须维护着与整个”buckets vector”的关系,并记录目前所指向的节点,如果目前节点是list的尾端,就跳到下一个bucket身上的list头部节点
注意这个迭代器没有operator–操作
开链的插入操作
- 如果新增元素计入后的元素个数>bucket.size(),需要重建表格(寻找下一个满足要求的质数,这个质数必定刚好大于元素个数),处理每个旧的bucket,再处理每个旧的bucket中的每个节点,将旧的节点放入新的计算出来的bucket的对应的list中
- 不需要重建表格,计算应该放入哪个bucket中,(假设键值不允许重复)如果遇到重复的节点,直接返回插入失败,将节点插到链表的末尾
印证
这里看到程序的输出顺序完全是乱的,找不到任何规律,也印证了其中的哈希结构
std::unordered_map<std::string, int> umap = {
{"watermelon", 4},
{"apple", 1},
{"banana", 2},
{"cherry", 3}
};
// 使用迭代器遍历 unordered_map
for (auto it = umap.begin(); it != umap.end(); ++it) {
std::cout << it->first << " => " << it->second << std::endl;
}
/*apple = > 1
watermelon = > 4
cherry = > 3
banana = > 2*/